TikTok and the Sorting Hat
I often describe myself as a cultural determinist, more as a way to differentiate myself from people with other dominant worldviews, though I am not a strict adherent. It’s more that in many situations when people ascribe causal power to something other than culture, I’m immediately suspicious.
The 2010’s were a fascinating time to follow the consumer tech industry in China. Though I left Hulu in 2011, I still kept in touch with a lot of the team from our satellite Hulu Beijing office, many of whom scattered out to various Chinese tech companies throughout the past decade. On my last visit to the Hulu Beijing office in 2011, I was skeptical any of the new tech companies out of China would ever crack the U.S. market.
It wasn’t just that the U.S. had strong incumbents, or that the Chinese tech companies were still in their infancy. My default hypothesis was that what I call the veil of cultural ignorance was too impenetrable a barrier. That companies from non-WEIRD countries (Joseph Henrich shorthand for Western, Educated, Industrialized, Rich, and Democratic) would struggle to ship into WEIRD cultures. I was even skeptical of the reverse, of U.S. companies competing in China or India. The further the cultural distance between two countries, the more challenging it would be for companies in one to compete in the other. The path towards overcoming that seemed to lie in hiring a local leadership team, or sending someone over from the U.S. who understood the culture of that country inside-out.
For the most part, that has held true. China has struggled, for the most part, to make real inroads in the U.S. WeChat tried to make inroads in the U.S. but only really managed to capture Chinese-Americans who used the app to communicate with friends, family, and business colleagues in China.
In the other direction, the U.S. hasn’t made a huge dent in China. Obviously, the Great Firewall played a huge role in keeping a lot of U.S. companies out of the Chinese market, but in the few cases where a U.S. company got a crack at the Chinese market, like Uber China, the results were mixed.
For this reason, I’ve been fascinated with TikTok. Here in 2020, TikTok is, for many, including myself, the most entertaining short video app going. The U.S. government is considering banning the app as a national security risk, and while that’s the topic du jour for just about everyone right now, I’m much more interested in tracing how it got a foothold in markets outside of China, especially the U.S. with its powerful incumbents.
They say you learn the most from failure, and in the same way I learn the most about my mental models from the exceptions. How did an app designed by two guys in Shanghai managed to run circles around U.S. video apps from YouTube to Facebook to Instagram to Snapchat, becoming the most fertile source for meme origination, mutation, and dissemination in a culture so different from the one in which it was built?
The answer, I believe, has significant implications for the future of cross-border tech competition, as well as for understanding how product developers achieve product-market-fit. The rise of TikTok updated my thinking. It turns out that in some categories, a machine learning algorithm significantly responsive and accurate can pierce the veil of cultural ignorance. Today, sometimes culture can be abstracted.
TikTok's story begins in 2014, in Shanghai. Alex Zhu and Luyu “Louis” Yang had launched an educational short-form video app that hadn’t gotten any traction. They decided to pivot to lip-synch music videos, launching Musical.ly in the U.S. and China. Ironically, the app got more traction across the Pacific Ocean, so they killed their efforts in their home country of China and focused their efforts on their American market.
The early user base consisted mostly of American teenage girls. Finally, an app offered users the chance to lip synch to the official version of popular songs and have those videos distributed to an audience for social feedback.
That the app got any traction at all was progress. However, it presented Alex, Louis, and their team with a problem. American teen girls were not exactly an audience Alex and Louis really understood.To be fair, most American parents would argue they don't understand their teenage daughters either.
During this era where China and the U.S. tech scenes have overlapped, the Chinese market has been largely impenetrable to the U.S. tech companies because of the Great Firewall, both the software instance and the outright bans from the CCP. But in the reverse direction, America has been almost as impenetrable to Chinese companies because of what might be thought of as America’s cultural firewall. Outside of DJI in dronesI'd argue one reason DJI had success in America was that drone control interfaces borrow heavily from standard flight control interfaces and are not culturally specific. Thus DJI could lean on its hardware prowess which was formidable., I can’t think of any Chinese app making real inroads in the U.S. prior to Musical.ly. To build on its early traction, Musical.ly would have to overcome this cultural barrier.
It’s been said that if you ask your customers what they want, they’ll ask for a faster horse (attributed to Henry Ford, though that may not be true). Frankly, that’s always been half horses***, and not just because horses are involved. First of all, what if your customers are horse jockeys?
Secondly, while you can’t listen to your customers exclusively, paying attention to them is a dependable way to build a solid SaaS business, and even in the consumer space it provides useful signal. As I’ve written about before, customers may tell you they want a faster horse, and what you should hear is not that you should be injecting your horses with steroids but that your customers find their current mode of transportation, the aforementioned horse, to be too slow a means of getting around.
Alex and Louis listened to Musical.ly’s early adopters. The app made feedback channels easy to find, and the American teenage girls using the app every day were more than willing to speak up about what they wanted to ease their video creation. They sent a ton of product requests, helping to inform a product roadmap for the Musical.ly team. That, combined with some clever growth hacks, like allowing watermarked videos to easily be downloaded and distributed via other networks like YouTube, Facebook, and Instagram, helped them achieve hockey-stick inflection among their target market.
Still, Musical.ly ran into its invisible asymptote eventually. There are only so many teenage girls in the U.S. When they saturated that market, usage and growth flatlined. It was then that a suitor they had rebuffed previously, the Chinese technology company Bytedance, suddenly looked more attractive, like Professor Bhaer to Jo March at the end of Little Women. In a bit of dramatic irony, Bytedance had cloned Musical.ly in China with an app called Douyin, one that had taken off in China, and now Bytedance was buying the app that inspired it, Musical.ly, an app conceived and built in China but that had failed in China and instead gotten traction in the U.S.
After the purchase, Bytedance rebranded Musical.ly as TikTok. Still, if that’s all they had done, it’s not clear why the app would’ve broken out of its stalled growth to the stunning extent it has under its new owner. After all, Bytedance paid just $1B for an app that’s rumored to sell now, if the U.S. government approves the transaction, for anywhere from $30 to $70B.
Bytedance did two things in particular to jumpstart TikTok’s growth.
First, it opened up its wallet and started spending on user acquisition in the U.S. the way wealthy Chinese used to spend on American real estate (no, I’m not still bitter at all the Chinese all-cash offers that trounced me repeatedly when condo-hunting six years ago). TikTok was rumored to have been spending a staggering eight or nine figures a month on advertising.
The ubiquity of TikTok ads lent the theory credence. I saw TikTok ads everywhere, on YouTube, Instagram, Twitter, Facebook, and in mobile gamesTikTok ads are bizarre. The video ads I see for the app in mobile games convey nothing about what the app is or does. One ad I've seen dozens of times has an old lady doing lunges in her living room, another has a kid blow drying his hair, and as he does, his hair changes colors. I feel like the ads could do a better job of selling the app, but what do I know?. If Bytedance could have purchased ads on the back of my eyelids at sub $20 CPMs I don’t doubt they would have done so.
It didn’t look like a wise investment at first. Rumors abounded that the 30-day retention of all those new users poured into the top of its funnel was sub 10%. They seemed to be lighting ad dollars on fire.
Ultimately, the ROI on that spend would turn the corner, but only because of the second element of their assault on the US market, the most important piece of technology Bytedance introduced to TikTok: the updated For You Page feed algorithm.
Bytedance has an absurd proportion of their software engineers focused on their algorithms, more than half at last check. It is known as the algorithm company, first for its breakout algorithmic “news” app Toutiao, then for its Musical.ly clone Douyin, and now for TikTok.
Prior to TikTok, I would’ve said YouTube had the strongest exploit algorithm in video,The exploit versus explore conundrum is sort of a classic of algorithmic design, usually mentioned in relation to the multi-armed bandit problem. For the purposes of this discussion, think of it simply as the problem of choosing which videos to show you. An exploit algorithm will give you more of what you like, while an explore algorithm tries to broaden your exposure to more than just what you’ve shown you like. YouTube is often described as an exploit algorithm because it tends to really push more of what you like, and then before you know it, you’re looking at some alt-right video that’s trying to redpill you. but in comparison to TikTok, YouTube’s algorithm feels primitive (the top creators on YouTube have long ago figured out how to game YouTube’s algorithm’s heavy dependence on click-through rates and watch time, one reason so many YouTube videos are lengthening over time, much to my dismay).
Before Bytedance bought Musical.ly and rebranded it TikTok, its Musical.ly clone called Douyin was already a sensation in the Chinese market thanks in large part to its effective algorithm. A few years ago, on a visit to Beijing, I caught up with a bunch of former colleagues from Hulu Beijing, and all of them showed me their Douyin feeds. They described the app as frighteningly addictive and the algorithm as eerily perceptive. More than one of them said they had to delete the app off their phone for months at a time because they were losing an hour or two every night just lying in bed watching videos.
That same trip, I had coffee with an ex-Hulu developer who now was now a senior exec in the Bytedance engineering organization. Of course, he was tight-lipped about how their algorithm worked, but the scale of their infrastructure dedicated to their algorithms was clear. On my way in and out of this office, just one of several Bytedance spaces all across the city, I gawked at hundreds of workers sitting side by side in row after row in the open floorplan. It resembled what I’d seen at tech giants like Facebook in the U.S., but even denser.The mood was giddy. I could tell he was doing well. He took me and my friends to a Luckin Coffee in their office basement and told us to order drinks off an app on his phone. I reached in my pocket for some RMB to pay for the drinks and he put his hand on my arm to stop me. “Don’t worry, I can afford this,” he said, laughing. He didn’t mean it in a boasting manner, he seemed almost sheepish about how well they were doing. Afterwards, as we waited outside the office in their parking lot, he walked past and asked me if I needed a ride. No, I said, I’d be taking the subway. A Tesla Model X pulled up, the valet hopped out, and he jumped in and drove off.
It’s rumored that Bytedance examines more features of videos than other companies. If you like a video featuring video game captures, that is noted. If you like videos featuring puppies, that is noted. Every Douyin feed I examined was distinctive. My friends all noted that after spending only a short amount of time in the app, it had locked onto their palate.
That, more than anything else, was the critical upgrade Bytedance applied to Musical.ly to turn it into TikTok. Friends at Bytedance claimed, with some pride, that after they plugged Musical.ly, now TikTok, into Bytedance’s back-end algorithm, they doubled the time spent in the app. I was skeptical until I asked some friends who had some data on the before and after. The step change in the graph was anything but subtle.
At the time Musical.ly got renamed TikTok, it was still dominated by teen girls doing lip synch videos. Many U.S. teens at the time described TikTok as “cringey,” usually a kiss of death for networks looking to expand among youths, fickle as they are about what’s cool. Scrolling the app at the time felt like eavesdropping on the theater kids clique from high school. Entertaining, but hardly a mainstream entertainment staple.
That’s where the one-two combination of Bytedance’s enormous marketing spend and the power of TikTok’s algorithm came to the rescue. To help a network break out from its early adopter group, you need both to bring lots of new people/subcultures into the app—that’s where the massive marketing spend helps—but also ways to help these disparate groups to 1) find each other quickly and 2) branch off into their own spaces.
More than any other feed algorithm I can recall, Bytedance’s short video algorithm fulfilled these two requirements. It is a rapid, hyper-efficient matchmaker. Merely by watching some videos, and without having to follow or friend anyone, you can quickly train TikTok on what you like. In the two sided entertainment network that is TikTok, the algorithm acts as a rapid, efficient market maker, connecting videos with the audiences they’re destined to delight. The algorithm allows this to happen without an explicit follower graph.
Just as importantly, by personalizing everyone’s FYP feeds, TikTok helped to keep these distinct subcultures, with their different tastes, separated. One person’s cringe is another person’s pleasure, but figuring out which is which is no small feat.
TikTok’s algorithm is the Sorting Hat from the Harry Potter universe. Just as that magical hat sorts students at Hogwarts into the Gryffindor, Hufflepuff, Ravenclaw, and Slytherin houses, TikTok’s algorithm sorts its users into dozens and dozens of subculturesThe Sorting Hat is perhaps the most curious plot device from the Harry Potter universe. Is it a metaphor for genetic determinism? Did Draco have any hope of not being a Slytherin? By sorting Draco into that house, did it shape his destiny? Is the hat a metaphor for the U.S. college admissions system, with all its known biases? Is Harry Potter, sorted into Gryffindor, a legacy admit?. Not two FYP feeds are alike.
For all the naive and idealistic dreams of the so-called “marketplace of ideas,” the first generation of large social networks has proven mostly unprepared and ill-equipped to deal with the resulting culture wars. Until they have some real substantial ideas and incentives to take on the costly task of mediating between strangers who disagree with each other, they’re better off sorting those people apart. The only types of people who enjoy being thrown into a gladiatorial online arena together with those they disagree with seem to be trolls, who benefit asymmetrically from the resultant violence.
Consider Twitter's content moderation problems. How much of that results from throwing liberals and conservatives together in a timeline together? Twitter employees speak often about wanting to improve public discourse, but they’d be much better off (and society, too) keeping the Slytherins and Gryffindors apart until they have some real substantive ideas to solve the problem of low trust conversation.The same can be said of NextDoor and their problem of racist reporting of minorities just walking down the sidewalk. They’d be better off just removing that feature. At some point, NextDoor needs to face the fact that they aren’t going to solve racism. Tweak that feature all you want, put up all the hoops for users to jump through to file such a report, but adverse selection ensures that those most motivated to jump through them are the racist ones.
After some time, new subcultures did indeed emerge on TikTok. No longer was it just teenage girls lip-synching. There are so many subcultures on TikTok I can barely track them because I only ever see a portion of them in my personalized FYP. This broadened TikTok’s appeal and total addressable market. Douyin had followed that path in China, so Bytedance at least had some precedent for committing to such an expensive bet, but I wasn’t certain if it would work in the U.S., a much more competitive media and entertainment market.
Within a larger social network, even subcultures need some minimum viable scale, and though Bytedance paid dearly to fill the top of the funnel, its algorithm eventually helped assemble many subcultures surpassing that minimum viable scale. More notably, it did so with amazing speed.
Think of how most other social networks have scaled. The usual path is organic. Users are encouraged to follow and friend each other to assemble their own graph one connection at a time. The challenge with that is that it’s almost always a really slow build, and you have to provide some reason for people to hang around and build that graph, often encapsulated by the aphorism “come for the tool, stay for the network.” Today, it’s not as easy to build the “tool” part when so much of that landscape has already been mined and when scaled networks have learned to copy any tool achieving any level of traction.In the West, Facebook is the master of the fast follow. They struggle to launch new social graphs of their own invention, but if they spot any competing social network achieve any level of traction, they will lock down and ship a clone with blinding speed. Good artists borrow, great artists steal, the best artists steal the most quickly? Facebook as a competitor reminds me of that class of zombies in movies that stagger around drunk most of the time, but the moment they spot a target, they sprint at it like a pack of cheetahs. The type you see in 28 Days Later and I Am Legend. Terrifying.
Some people still think that a new social network will be built around a new content format, but it’s almost impossible to think of a format that couldn’t be copied in two to three months by a compact Facebook team put in lockdown with catered dinners. Yes, a new content format might create a new proof of work, as I wrote about in Status as a Service, but just as critical is building the right structures to distribute such content to the right audience to close the social feedback loop.
What’s the last new social network to achieve scale in recent years? You probably can’t think of any, and that’s because there really aren’t any. Even Facebook hasn’t been able to launch any really new successful social products, and a lot of that is because they also seem fixated on building these things around some content format gimmick.
Recall the three purposes which I used to distinguish among networks in Status as a Service: social capital (status), entertainment, and utility. In another post soon I promise to explain why I classify networks along these three axes, but for now, just know that while almost all networks serve some mix of the three, most lean heavily towards one of those three purposes.
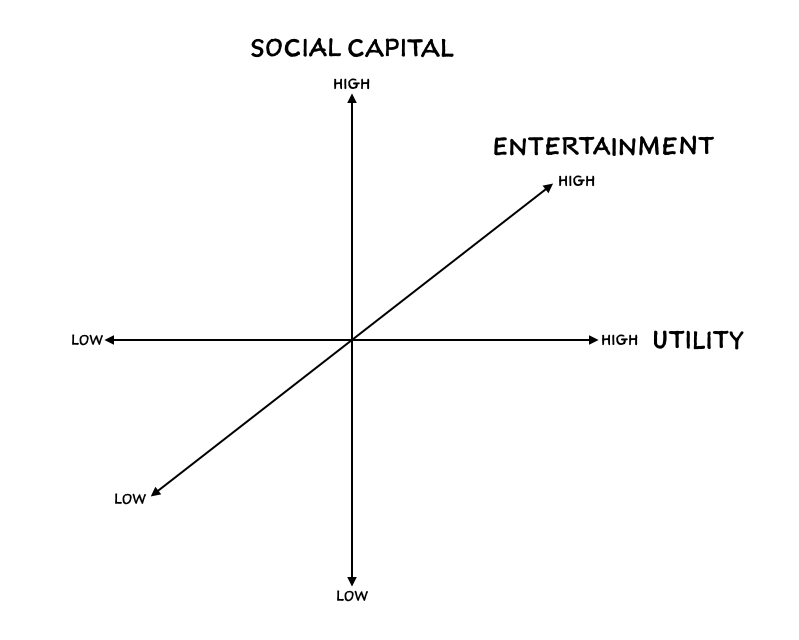
A network like Venmo or Uber, for example, is mostly about utility: I need to pay someone money, or I need to travel from here to there. A network like YouTube is more about entertainment. Amuse me. And some networks, what most people refer to when they use the generic term “social network,” are more focused on social capital. Soho House, for example.
TikTok is less a pure social network, the type focused on social capital, than an entertainment network. I don’t socialize with people on TikTok, I barely know any of them. It consists of a network of people connected to each other, but they are connected for a distinct reason, for creators to reach viewers with their short videos.Bytedance hasn't been successful in building out a social network to compete with WeChat, though it's not for lack of trying. I think they have a variety of options for doing so, but as with many companies that didn't begin as social first, it's not in their DNA. Facebook is underrated for its ability to build functional social plumbing at scale, that is a rare design skill. Companies as diverse as Amazon and Netflix have tried building social features and then later abandoned them. I suspect they tried when they didn't have enough users to create breakaway social scale, but it's difficult to imagine them pulling that off without more social DNA. But having a social-first DNA also means that Facebook isn't great at building non-social offerings. Their video or watch tab remains a bizarre and unfocused mess.
One can debate the semantics of what constitutes a social network forever, but what matters here is realizing that another way to describe an entertainment network is as an interest network. TikTok takes content from one group of people and match it to other people who would enjoy that content. It is trying to figure out what hundreds of millions of viewers around the world are interested in. When you frame TikTok's algorithm that way, its enormous unrealized potential snaps into focus.
The idea of using a social graph to build out an interest-based network has always been a sort of approximation, a hack. You follow some people in an app, and it serves you some subset of the content from those people under the assumption that you’ll find much of what they post of interest to you. It worked in college for Facebook because a bunch of hormonal college students are really interested in each other. It worked in Twitter, eventually, though it took a while. Twitter's unidirectional follow graph allowed people to pick and choose who to follow with more flexibility than Facebook's initial bi-directional friend model, but Twitter didn't provide enough feedback mechanisms early on to help train its users on what to tweet. The early days were filled with a lot of status updates of the variety people cite when criticizing social media: "nobody cares what you ate for lunch."I talk about Twitter's slow path to product market fit in Status as a Service
But what if there was a way to build an interest graph for you without you having to follow anyone? What if you could skip the long and painstaking intermediate step of assembling a social graph and just jump directly to the interest graph? And what if that could be done really quickly and cheaply at scale, across millions of users? And what if the algorithm that pulled this off could also adjust to your evolving tastes in near real-time, without you having to actively tune it?
The problem with approximating an interest graph with a social graph is that social graphs have negative network effects that kick in at scale. Take a social network like Twitter: the one-way follow graph structure is well-suited to interest graph construction, but the problem is that you’re rarely interested in everything from any single person you follow. You may enjoy Gruber’s thoughts on Apple but not his Yankees tweets. Or my tweets on tech but not on film. And so on. You can try to use Twitter Lists, or mute or block certain people or topics, but it’s all a big hassle that few have the energy or will to tackle.
Think of what happened to Facebook when it’s users went from having their classmates as friends to hundreds and often thousands of people as friends, including coworkers, parents, and that random person you met at the open bar at a wedding reception and felt obligated to accept a friend request from even though their jokes didn’t seem as funny the next morning in the cold light of sobriety. Some have termed it context collapse, but by any name, it’s an annoyance everyone understands. It manifests itself in the declining visit and posting frequency on Facebook across many cohorts.
Think of Snapchat’s struggles to differentiate between its utility— as a way to communicate among friends—and its entertainment function as a place famous people broadcast content to their fans. In a controversial redesign, Snapchat cleaved the broadcast content from influencers into the righthand Discover tab, leaving your conversations with friends in the left Chat pane. Look, the redesign seemed to say, Kylie Jenner is not your friend.
TikTok doesn’t bump into the negative network effects of using a social graph at scale because it doesn't really have one. It is more of a pure interest graph, one derived from its short video content, and the beauty is its algorithm is so efficient that its interest graph can be assembled without imposing much of a burden on the user at all. It is passive personalization, learning through consumption. Because the videos are so short, the volume of training data a user provides per unit of time is high. Because the videos are entertaining, this training process feels effortless, even enjoyable, for the user.
I like to say that “when you gaze into TikTok, TikTok gazes into you.” Think of all the countless hours product managers, designers and engineers have dedicated to growth-hacking social onboarding—goading people into adding friends and following people, urging them to grant access to their phone contact lists—all in an attempt to carry them past the dead zone to the minimum viable graph size necessary to provide them with a healthy, robust feed. (sidenote: Every social product manager has heard the story of Facebook and Twitter’s keystone metrics for minimum viable friend or follow graph size countless times.) Think of how many damn interest bubble UI’s you’ve had to sit through before you could start using some new social product: what subjects interest you? who are your favorite musicians? what types of movies do you enjoy?The last time I tried to use Twitter’s new user onboarding flow, it recommended I follow, among other accounts, that of Donald Trump. There are countless ways they could onboard people more efficiently to provide them with a great experience immediately, but that is not one of them.
TikTok came along and bypassed all of that. In a two-sided entertainment marketplace, they provide creators on one side with unmatched video creation tools coupled with potential super-scaled distribution, and viewers on the other side with an endless stream of entertainment that gets more personalized with time. In doing so, TikTok, with a product team and infrastructure mostly located in China, came out of left field and became a player in the attention marketplace on the same playing fields around the world as giants like Facebook, Instagram, Snapchat, YouTube, and Netflix. Not quite a Cinderella story...maybe a Mulan story?
TikTok didn't just break out in America. It became unbelievably popular in India and in the Middle East, more countries whose cultures and language were foreign to the Chinese Bytedance product teams. Imagine an algorithm so clever it enables its builders to treat another market and culture as a complete black box. What do people in that country like? No, even better, what does each individual person in each of those foreign countries like? You don't have to figure it out. The algorithm will handle that. The algorithm knows.
I don’t think the Chinese product teams I’ve met in recent years in China are much further ahead than the ones I met in 2011 when it comes to understanding foreign cultures like America. But what the Bytedance algorithm did was it abstracted that problem away.One of the concerns about CCP ties with Bytedance is that they might use it as a propaganda tool against the U.S. I tend to think that problem is overrated because my sense is that many in China still don't understand the nuances of American culture, just as America doesn't understand theirs (though I speak Mandarin, some of the memes on Douyin fly way over my head). However, perhaps an algorithm that abstracts culture into a series of stimuli responses makes it more dangerous?
Now imagine that level of hyper efficient interest matching applied to other opportunities and markets. Personalized TV of the future? Check. Education? I already find a lot of education videos in my TikTok feed, on everything from cooking to magic to iPhone hacks. Scale that up and Alex and Louis might finally realize their dream of a short video education app that they set out to build before Musical.ly.
Shopping? A slam dunk, Douyin and Toutiao already enable a ton of commerce in China. Job marketplace? A bit of a stretch, but not impossible. If Microsoft buys TikTok, I’d certainly give the TikTok team a crack at improving my LinkedIn feed, which, to be clear, is horrifying. What about personalized reading, from books to newsletters to blogs? Music? Podcasts? Yes, yes, yes please. Dating? The world could absolutely use an alternative to the high GINI co-efficient, high inequality dating marketplace that is Tinder.
Douyin already visualizes much of this future for us with its much broader diversity of videos and revenue models. In China, video e-commerce is light years ahead of where it is in the U.S. (for a variety of reasons, but none that aren’t surmountable; a topic, again, for another piece). Whereas TikTok can still feel, to me, like a pure entertainment time-killer, Douyin, which I track on a separate phone I keep just to run Chinese apps for research purposes, feels like much more than that. It feels like a realization of short video as a broad use case platform.
There’s a reason that many people in the U.S. today describe social media as work. And why many, like me, have come to find TikTok a much more fun app to spend time in. Apps like Facebook, Instagram, and Twitter are built on social graphs, and as such, they amplify the scale, ubiquity, and reach of our performative social burden. They struggle to separate their social functions from their entertainment and utility functions, injecting an aspect of social artifice where it never used to exist.
Facebook has struggled with its transition to utility, which would’ve offered it a path towards becoming more of a societal operating system the way WeChat is in China. To be fair, the competition for many of those functions is much stiffer in the U.S. In payments, for example, Facebook must compete with credit cards, which work fine and which most people default to in the U.S., whereas in China AliPay and WeChat Pay were competing with a cash-dominant culture. Still, in the U.S., Facebook has yet to make any real inroads in significant utility use cases like commerce.I speak so often about how much video as a medium is underrated by tech elites. In an alternate history of Facebook, they would've made a harder shift to becoming a video-only app, moving up the ladder from text to photos to videos, and maybe they would've become TikTok before TikTok. If they had, I think their time spent figures would be even higher today. For as quickly as Facebook moved to disrupt itself in the past, there's a limit to how far they're willing to go. I plan to compare the Chinese and U.S. tech ecosystems in a future post, and one of the broadest and most important takeaways is that China leapfrogged the U.S. in the shift to video, among many other things. This doesn't mean the U.S. won't then leapfrog China the next time around, but for now, the U.S. is the trailing frog in several categories.
Instagram is some strange hybrid mix of social and interest graph, and now it’s also a jumble of formats, with a Stories feed relegated to a top bar in the app while the more stagnant and less active original feed continues to run vertically as the default. Messaging is pushed to a separate pane and also served by a separate app. Longer form videos bounce you to Instagram TV, which is just an app for videos that exceed some time limit, I guess? And soon, perhaps commerce will be jammed in somehow? Meanwhile, they have a Discover tab, or whatever it is called, which seems like it could be the default tab if they wanted to take a more interest-based approach like TikTok. But they seem to have punted on making any hard decisions for so long now that the app is just a Frankenstein of feeds and formats and functions spread across a somewhat confused constellation of apps.
Twitter has never seemed to know what it is. Ask ten different Twitter employees, you’ll hear ten different answers. Perhaps that’s why the dominant product philosophy of the company seems to be a sort of constant paralysis broken up by the occasional crisis mitigation. One reason I’ve long wished Twitter had just become a open protocol and let the developer community go to town is that Twitter moves. At. A. Snail's. Pace.
The shame of it is that Twitter had a head start on an interest graph, largely through the work of its users, who gave signal on what they cared about through the graphs they assembled. That could have been a foundation to all sorts of new markets for them. They could’ve even been an interest-based social network, but instead users have mostly extracted that value themselves by pinging each other through the woefully neglected DM product.Of course, Twitter also once purchased Vine and then let it wither on the, uh vine. Of all the tech companies that could purchase TikTok, maybe Twitter is the one that least deserves it. At a minimum, they should be required to submit a book report showing they understand what it is they're buying.
A few other tech companies are worth mentioning here. YouTube is a massive video network, but honestly they may have shipped even less than Twitter over the years. That they don’t have any video creation tools of note (do they have any?!) and allowed TikTok to come in and steal the short video space is both shocking and not.
Amazon launched a short video commerce app some time ago. It came and went so quickly I didn’t even have time to try it. Though Amazon is good at many things, they just don’t have the DNA to build something like TikTok. That they have failed to realize the short video commerce vision that China led the way on is a shocking miss on their part.
Apple owns the actual camera that so many of these videos are shot on, but they've never understood social.iMessages could be a social networking colossus if Apple had the social DNA, but every day other messaging apps pull further away in functionality and design. But I guess they're finally adding threading in iMessages with the next iOS release? Haha. At least they'll continue to improve the camera hardware with every successive iPhone release.
None of this is to say TikTok is anywhere near the market value of any of these aforementioned American tech giants. If you still think of it as a novelty meme short video app, you're not far from the truth.Are there flaws with TikTok? Of course. It’s far from perfect. The algorithm can be too clingy. Sometimes I like one video from some meme and the next day TikTok serves me too many follow-up videos from the same meme. But the great thing about a hyper-responsive algorithm is that you can tune it quickly, almost like priming GPT-3 to get the results you want. Often all it takes to inject some new subculture into your TikTok feed is to find some video from it (you can easily find them on YouTube or via friends whose feeds are different from your own) and like it. Another problem for TikTok is that a lot of other use cases are being jammed into what was designed to be a portrait mode lip synch video app. Vertical video is good for the human figure, for dance and makeup videos, but not ideal for other types of communication and storytelling (I still hate when basketball and football highlight clips can’t show more of the horizontal playing field, and that goes for both IG and TikTok; in many highlights of Steph Curry hitting a long 3 you can’t see him, or the basket, only one of the two, lol). Stepping up a level, the list of opportunities Bytedance and TikTok have yet to capitalize on in the U.S. is long, and it wouldn’t surprise me if they miss many of them even if they stave off a ban from the U.S. government. Much of it would require new form factors, and it’s unclear how strong the TikTok product team would be, especially if divested out of Bytedance. Under Microsoft, a company with a fairly shaky history in the consumer market, it's unclear that their full potential would be realized.
Still, none of that product work is rocket science. Much of it seems clear in my head. More importantly, TikTok, if armed with the Bytedance algorithm as part of a divestment, has a generalized interest-matching algorithm that can allow it to tackle U.S. tech giants not head on but from an oblique angle. To see it as merely a novelty meme video app for kids is to miss what its much greater disruptive potential. That an app launched out of China could come to the U.S. and sprint into cultural relevance in this attention marketplace should be a wake-up call to complacent U.S. tech companies. Given how many of those companies rely on intuiting user interests to sell them things or to show them ads, a company like TikTok which found a shortcut to assembling such an interest graph should raise all sorts of alarm bells.
It surprises me that more U.S. tech companies aren’t taking a harder run at trying to acquire TikTok if the rumored CFIUS hammer stops short of an outright ban. I can’t think of any of them that shouldn’t be bidding for what is a once-in-a-generation forced fire sale asset. I’ve seen prices like $30B tossed around online. If that’s true, it’s an absolute bargain. I’d easily pay twice that without a second thought.
I could cycle through my long list of nits, but ultimately they are all easily solvable with the right product vision and execution. TikTok has figured out the hardest piece, the algorithm. With it, a massive team made up mostly by people who’ve never left China, and many who never will, grabbed massive marketshare in cultures and markets they’d never experienced firsthand. To a cultural determinist like myself, that feels like black magic.
On that same trip to China in 2018 when I visited Bytedance, an ex-colleague of mine from Hulu organized a visit for me to Newsdog. It was a news app for the Indian market built by a startup headquartered in Beijing. As I exited the elevator into their lobby, I was greeted by a giant mural of Jeff Bezos’ famous saying “It’s Always Day One” on the opposite wall.
A friend of a friend was the CEO there, and he sat me down in a conference room to walk me through their app. They had raised $50M from Tencent just a few months earlier that year, and they were the number one news app in India at the time.
He opened the app on his phone and handed it to me. Similar to Toutiao in China, there were different topic areas in a scrollbar across the top, with a vertical feed of stories beneath each. All of these were stories selected algorithmically, as is the style of Toutiao and so many apps in China.
I looked through the stories, all in Hindi (and yes, one feed that contained the thirst trap photos of attractive Indian girls in rather suggestive outfits standing under things like waterfalls; some parts of culture are universal). Then I looked up from the app and through the glass walls of the conference room at an office filled with about 40 Chinese engineers, mostly male, tapping away on their computers. Then I looked back down at page after page of Hindi stories in the app.
“Wait,” I asked. “Do you have people in this office or at the company who know how to read Hindi?”
He looked at me with a smile.
“No,” he said. “None of us can read any of it.”
NEXT POST: Part II of my thoughts on TikTok, on how the app design is informed by its algorithm and vice versa in a virtuous circle.